In this post, I'm going to talk about drawing trees and graphs programatically.
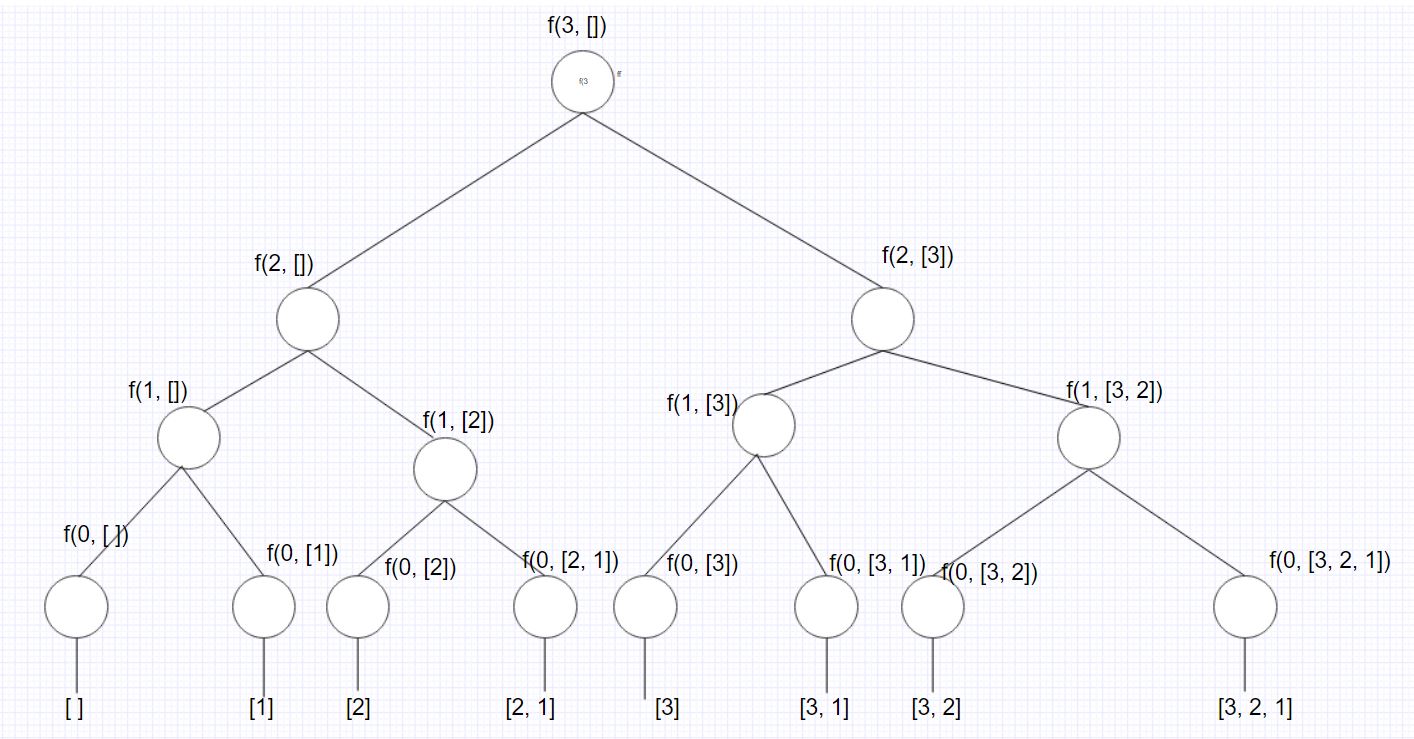
I've written several answers on quora regarding recursion where I had to manually draw recursion tree as in Finding Subsets Solution
 I'll try to visulise this recursion tree programatically in the second part of this Visualisation with Pydot
But before that, let's learn some basc concepts:
I'll try to visulise this recursion tree programatically in the second part of this Visualisation with Pydot
But before that, let's learn some basc concepts:
I'll be using pydot, which is a Python interface for Graphviz which is an awesome tool for Grah visualisation. So let's get started.
First thing first, we'll first setup the environment for graphviz. Let's download the graphviz binary from here. I'll be using a windows 10 64bit machine for this tutorial and install it. Now we have to add graphviz bin folder to the environment variable path. If you are having trouble here is the installation guide.
Let's install pydot by using:
 Here is how the output looks like. Cool, right?? We'll be exploring more options later on.
Now let's say we want to change show a directed edge from node 1 to 2 and node 1 to 3.
That's simple as changing the line
Here is how the output looks like. Cool, right?? We'll be exploring more options later on.
Now let's say we want to change show a directed edge from node 1 to 2 and node 1 to 3.
That's simple as changing the line
(

Now let's say we allow multiple edges from one node to another. Say, we want an edge from 1 -> 2, 1 -> 3 and another edge from 1 -> 2. This is easy, we can add another line

But what if we want to prevent another edge from drawing if it is already present.

We simply supllied another option
Now we have basic idea of drawing edges , let's eplore how we can add nodes on graph without any edges.

But what if you want 2 nodes with same name, Is it possible?
 Here we can see, we are only able to get 1 node with the name "1", so what's the fix?
Here we can see, we are only able to get 1 node with the name "1", so what's the fix?
We'll see another property of
 Can we make the graphs more attractive using different colors for nodes and edges?
Can we make the graphs more attractive using different colors for nodes and edges?

Now let's wrap up the tutorial by drawing some example graphs. First let's try drawing trees from google image results.



I'll be adding more on graphviz on Part II. Keep following... for more updates.
I'll be using pydot, which is a Python interface for Graphviz which is an awesome tool for Grah visualisation. So let's get started.
First thing first, we'll first setup the environment for graphviz. Let's download the graphviz binary from here. I'll be using a windows 10 64bit machine for this tutorial and install it. Now we have to add graphviz bin folder to the environment variable path. If you are having trouble here is the installation guide.
Let's install pydot by using:
pip install pydot
# Import pydot
import pydot
# Make Dot graph object of type graph
graph = pydot.Dot(graph_type='graph')
# Make Edge from 1 -> 2
graph.add_edge(pydot.Edge("1", "2"))
# Make Edge from 1 -> 3
graph.add_edge(pydot.Edge("1", "3"))
# Save the graph as png
graph.write_png("out.png")
(
# Make Dot graph object of type graph
graph = pydot.Dot(graph_type='graph')
graph = pydot.Dot(graph_type='digraph')
Now let's say we allow multiple edges from one node to another. Say, we want an edge from 1 -> 2, 1 -> 3 and another edge from 1 -> 2. This is easy, we can add another line
graph.add_edge(pydot.Edge("1", "3"))
But what if we want to prevent another edge from drawing if it is already present.
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='digraph', strict=True)
# Make Edge from 1 -> 2
graph.add_edge(pydot.Edge("1", "2"))
graph.add_edge(pydot.Edge("1", "2"))
graph.add_edge(pydot.Edge("1", "3"))
# Save the graph as png
graph.write_png("4.png")
We simply supllied another option
strict = True while making a dot graph object.Now we have basic idea of drawing edges , let's eplore how we can add nodes on graph without any edges.
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='digraph', strict=True)
# Make pydot Node obect with name 1
u = pydot.Node(name="1")
graph.add_node(u)
# Make pydot Node obect with name 2
v = pydot.Node(name="2")
graph.add_node(v)
# Save the graph as png
graph.write_png("out.png")
But what if you want 2 nodes with same name, Is it possible?
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='digraph', strict=True)
# Make pydot Node obect with name 1
u = pydot.Node(name="1")
graph.add_node(u)
# Make pydot Node obect with name 2
v = pydot.Node(name="1")
graph.add_node(v)
# Save the graph as png
graph.write_png("out.png")
We'll see another property of
pydot.Node called label.
What exactly is a label? It is the value that appears on Node whereas the name is the actual value that identifies the node.# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='digraph', strict=True)
u = pydot.Node(name="1", label="One")
graph.add_node(u)
v = pydot.Node(name="2", label="Two")
graph.add_node(v)
# Save the graph as png
graph.write_png("7.png")
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='digraph', strict=True)
u = pydot.Node(name="1", label="One", style="filled", fillcolor="gold")
graph.add_node(u)
v = pydot.Node(name="2", label="Two", style="filled", fillcolor="green")
graph.add_node(v)
# Save the graph as png
graph.write_png("8.png")
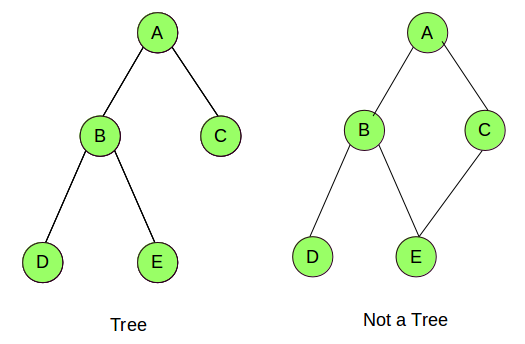
Now let's wrap up the tutorial by drawing some example graphs. First let's try drawing trees from google image results.
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='graph', strict=True)
x = pydot.Node("A", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("B", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("C", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("D", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("E", style="filled", fillcolor="green")
graph.add_node(x)
edge = pydot.Edge("A", "B")
graph.add_edge(edge)
edge = pydot.Edge("A", "C")
graph.add_edge(edge)
edge = pydot.Edge("B", "D")
graph.add_edge(edge)
edge = pydot.Edge("B", "E")
graph.add_edge(edge)
# Save the graph as png
graph.write_png("9.png")
# Import pydot
import pydot
# Make Dot graph obect of type graph
graph = pydot.Dot(graph_type='graph', strict=True)
x = pydot.Node("A", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("B", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("C", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("D", style="filled", fillcolor="green")
graph.add_node(x)
x = pydot.Node("E", style="filled", fillcolor="green")
graph.add_node(x)
edge = pydot.Edge("A", "B")
graph.add_edge(edge)
edge = pydot.Edge("A", "C")
graph.add_edge(edge)
edge = pydot.Edge("C", "E")
graph.add_edge(edge)
edge = pydot.Edge("B", "D")
graph.add_edge(edge)
edge = pydot.Edge("B", "E")
graph.add_edge(edge)
# Save the graph as png
graph.write_png("10.png")
Here is another question which asks to visualise recursion tree for nth fibonacci number.
def fib(n):
if n <= 1:
return n
return fib(n - 1) + fib(n - 2)
import pydot
i = 0
graph = pydot.Dot(graph_type="digraph")
parent = dict()
def fib(n, node_num):
global i
current_node = (n, node_num)
if node_num == 0:
u = pydot.Node(str((n, node_num)), label=f"fib({n})")
graph.add_node(u)
else:
# Draw edge from parent of current node and current node
u = pydot.Node(str(parent[current_node]), label=f"fib({parent[current_node ][0]})", style="filled", fillcolor="gold")
graph.add_node(u)
v = pydot.Node(str(current_node), label=f"fib({n})")
graph.add_node(v)
edge = pydot.Edge(str(parent[current_node]), str(current_node ))
graph.add_edge(edge)
if n <= 1:
# Draw Node for base cases
u = pydot.Node(str(current_node), label=f"fib({n})")
graph.add_node(u)
i += 1
v = pydot.Node(str((n, i)), label=f"{n}", shape="plaintext")
graph.add_node(v)
edge = pydot.Edge(str(current_node), str((n, i)), dir="backward")
graph.add_edge(edge)
return n
i += 1
# Store current node as the parent of left child
left_child = (n - 1, i)
parent[left_child] = current_node
i += 1
right_child = (n - 2, i)
parent[right_child] = current_node
#fib(n - 1) + fib(n - 2)
return fib(*left_child) + fib(*right_child)
n = 6
memo = dict()
parent[(n, 0)] = None
fib(n, 0)
graph.write_png("out.png")
I'll be adding more on graphviz on Part II. Keep following... for more updates.




{kind=link}